Nvidia представляет нейронную сеть размером 100 КБ с быстрым обучением
Недавно компания Nvidia представила свою нейронную сеть с названием Perfusion generative, которая отличается компактными размерами и возможностью быстрого обучения. По информации от Nvidia, для этой модели нейронной сети требуется всего 100 КБ памяти, что является удивительным достижением по сравнению с другими моделями, например, Midjourney, которым требуется более 2 гигабайт свободного пространства.
Perfusion - это новый метод, который позволяет преобразовывать текст в изображение с учетом персональных настроек. Модель этого имеет размер всего 100 КБ, что делает ее компактной (в отличие от предварительно обученных моделей, которые могут занимать несколько ГБ). Обучение модели занимает примерно 4 минуты.

Ключом к эффективности Perfusion является механизм, который Nvidia назвала «Key-Locking». Эта инновационная функция позволяет моделям связывать конкретные запросы пользователей с более широкой категорией или «надкатегорией». Например, запрос на создание кошки приводит модель к связыванию термина «кошка» с более общей категорией «кошачий». После этой связи модель обрабатывает дополнительные сведения, предоставленные в текстовом приглашении пользователя. Такой подход оптимизирует алгоритм, ускоряя обработку.

Этот метод позволяет управлять компромиссом между точностью визуального представления и выравниванием текста при выводе. Большое значение смещения уменьшает влияние концепции, а низкое значение делает ее более существенной. С помощью только одной обученной модели размером 100 КБ и выбора параметров в процессе выполнения, метод Perfusion (синий и голубой) охватывает весь фронт Парето.
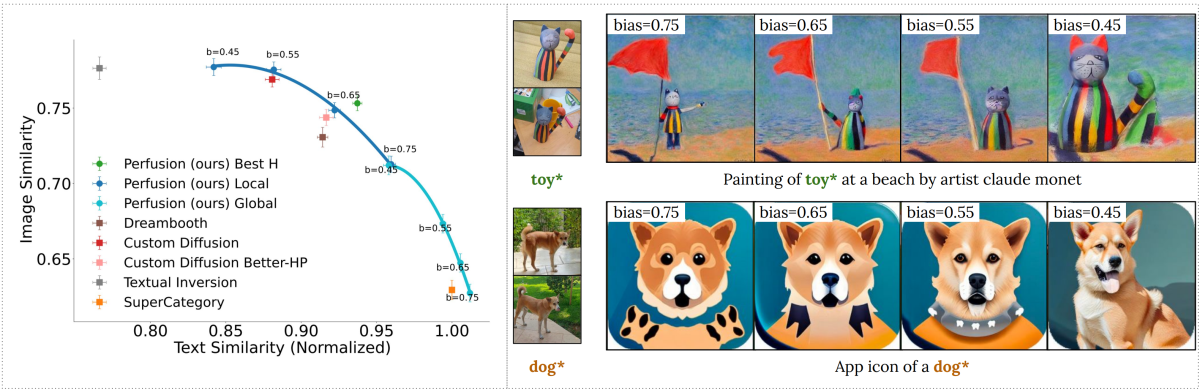
Наличие адаптивности является еще одним преимуществом модели Perfusion. Пользователь может настроить эту модель в соответствии с требованиями: либо строго следовать текстовой подсказке, либо предоставить некоторую "творческую свободу" в выходных данных. Такая универсальность гарантирует, что модель может быть точно настроена для достижения результатов, варьирующихся от точных до более общих, в зависимости от конкретных потребностей пользователя.
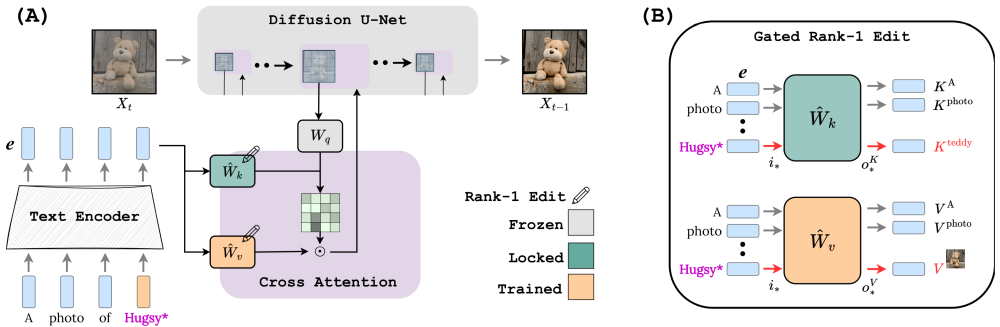
Архитектурная схема (А): подсказка превращается в последовательность кодировок. Каждая кодировка проходит через набор модулей перекрестного внимания (фиолетовые блоки) диффузионного шумоподавителя U-Net. Увеличенный фиолетовый модуль показывает, как пути ключа и значения зависят от кодировки текста. Ключ управляет картой внимания, которая затем модулирует путь Ценности.
Gated Rank-1 Настройка (B): Сверху: Путь K блокируется, поэтому любая кодировка